Services
Types of Audio Annotation:

It includes audio transcription, annotation and metadata. The type of annotations and metadata are fully tailored to the client's needs. From phonological, morphological, syntactic, semantic and discourse information to audio segmentation, speaker identification, turn taking, emotion, background noise, speech or music. You name it!

Be it verbatim or non-verbatim, our team will provide you with best-in-class transcriptions the way you want it, when you need it, in a cost-efficient way. Sigma offers scalable audio and video transcription services thanks to the optimal combination of our large base of vetted transcribers and our ML-assisted tools.
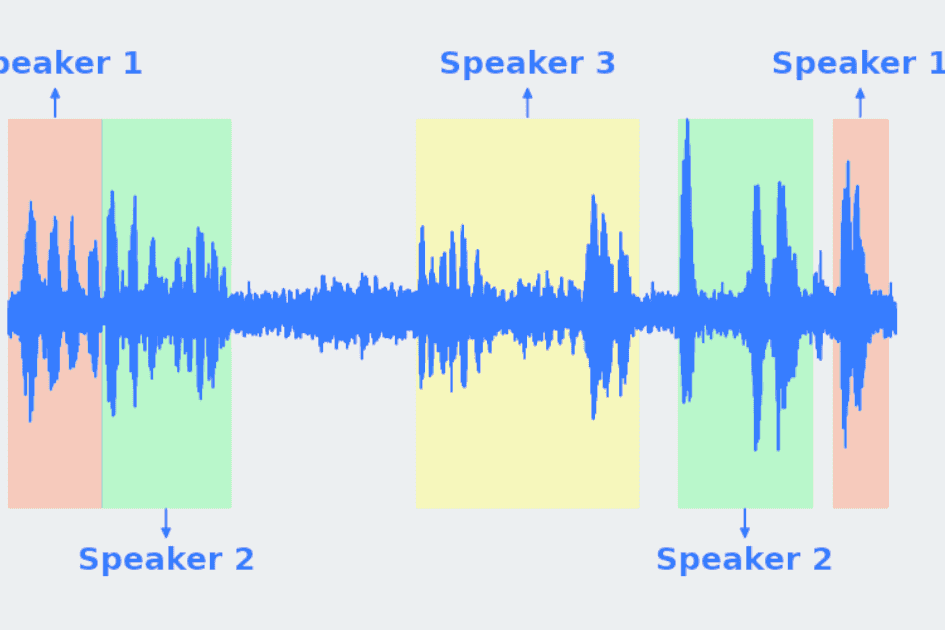
It consists of partitioning the input audio file into homogeneous audio segments according to their specific sources. These sources include the identity of the speakers whose voice is recorded in the audio file, music, silence, or background noise. This enables automating the process of analyzing any type of conversation, including call center dialogues and debates.

A phonetic transcription is very similar to a regular transcription, but instead of converting the audio into a sequence of words, it describes the way spoken words are pronounced using phonetic symbols. The most common alphabetic system of phonetic notation is the International Phonetic Alphabet (IPA).

Emotion annotation aims to determine feelings such as anger, happiness, sadness, fear, or surprise. It can be performed on text or audio data. Audio emotion analysis is more accurate since audio provides additional clues such as speech rate, pitch, pitch jumps, or voice intensity. Emotion detection helps improve human-machine communication, analyze call center dialogues, etc.

It is the process of determining if a segment of speech is perceived as positive, negative or neutral. Audio sentiment analysis is more accurate than text sentiment analysis since audio provides additional information such as the emotional state of the speakers. It helps gauge customers opinion, monitor brand/product reputation, customer experience and needs, social media, etc.

It consists of listening to the audio recording and classifying it into a series of predetermined categories. For example, categories that describe the user intent, the background noise, the quality of the recording, the topic, the number or type of speakers, the spoken language or dialect or semantic related information.
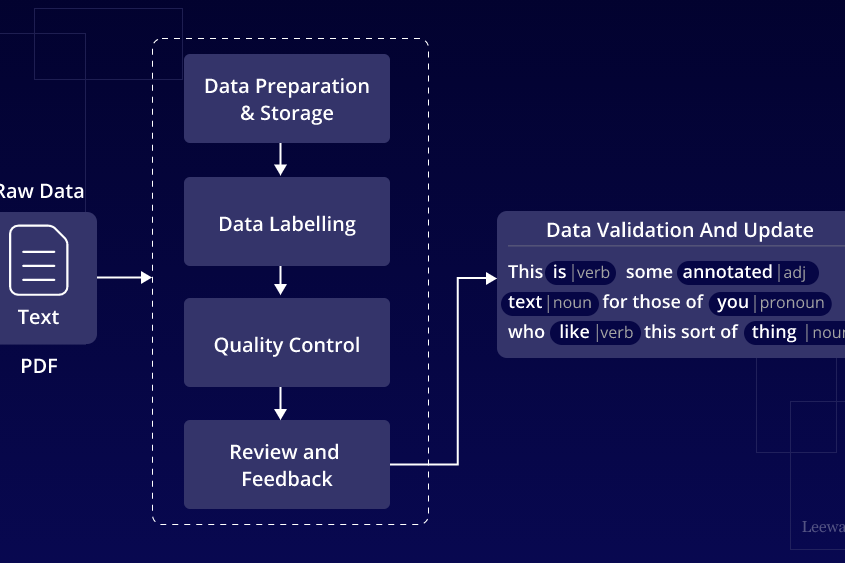
Data relevance provides information about the quality of data that a system delivers to its users. In particular, it determines to which extend the answer of a search engine or an intelligent assistant provides insight into the question of the user; i.e.: the level of consistency between the content of the data provided and the area of interest of the user.
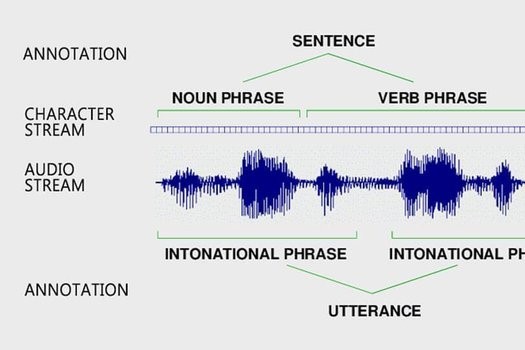
It aims to determine the accuracy of the speech annotations, including word error rate (substitutions, insertions and deletions), and label error rate according to the annotation guidelines. It helps assess the quality of the annotated speech in terms of accuracy and interpretation consistency of the annotation guidelines. It also helps complete the guidelines and resolve its ambiguities.

This quality assessment service provides information that helps optimize the effort in data collection and annotation. Quality is a multidimensional parameter that depends on factors such as the volume and quality of the audio, the accuracy of the annotations, the data consistency, the domain and customer’s coverage; and the balance. This helps focus the data collection and annotation effort where it is most needed.

This service measures the performance of the wake word detection, assesses if the pronunciation of the wake word and the subsequent voice commands belong to the same or several users, checks if the voice interactions are in the expected language, or if the answers of the assistant are correct based on the dialogue status and context as well as on the user data and the system knowledge database, etc.

The pronunciation assessment aims to determine whether the pronunciation of a word or sentence is correct. The correctness of the pronunciation can be performed by comparing it with the standard pronunciation or with the dialect variants. The pronunciation assessment can be performed on human or synthetic speech.