Understanding images is the key to creating machine learning models that can easily learn and understand the real world. Our image annotation service leads to better performing models.
One of the most popular uses of machine learning today is computer vision. It's in your phone camera and used to identify everything from people to text in photos. We know this is a crowded field, and we want to help. That's why our annotation experts are on hand to discuss how technology can make your business better.
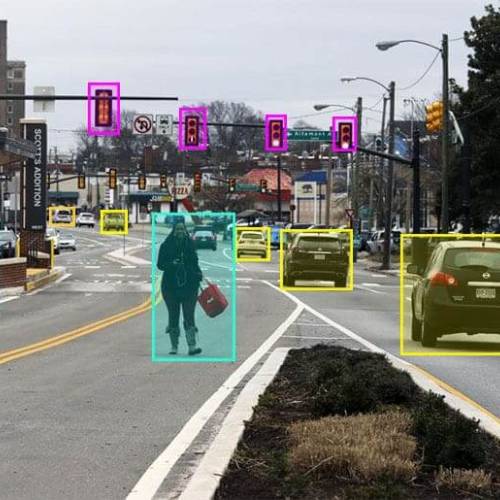
With our Image Annotation Service, you can easily train your own AI models to more accurately recognize the objects captured in images. To provide an accurate dataset for computer vision projects, data scientists and ML engineers need to label images.
To create a novel labelled dataset for use in computer vision projects, data scientists and ML engineers have the choice between a variety of annotation types they can apply to images. Researchers will use an image markup tool to help with the actual labelling.


Boost your AI with our expert image annotation!









